Table of Contents
SAP HANA Data Reclaim | Introduction
In the world of database management, one of the key tasks that often goes unnoticed is the process of SAP HANA data reclaim. This process, also known as defragmentation, is crucial for maintaining the efficiency and cost-effectiveness of your HANA Database (DB). This blog post aims to provide a detailed walk through of the SAP HANA Data Reclaim process in a DB cluster.
– Data reclamation serves a dual purpose:
1. Space Optimization: It helps in freeing up space within the HANA DB, thereby enhancing its performance.
2. Cost Efficiency: By reclaiming space, we can avoid the need for additional storage space in /hana/data, which directly translates to cost savings.
Why SAP HANA Data Reclaim | Causes of Fragmentation
There are several reasons why fragmentation occurs, leading to the availability of space that can be reclaimed or defragmented:
1. Business Data Reduction: This can occur due to archiving and deletion operations (Refer SAP Note 2388483 for more details).
2. Garbage Collection Blockage: Sometimes, the garbage collection process might get blocked, necessitating a cleanup (Refer SAP Note 2169283 for more details).
3. Table Optimization: Processes such as merge and compression of a large table can temporarily require double space (Refer SAP Note 2057046 for more details).
4. Preservation of Snapshots/Savepoints: If snapshots or savepoints are preserved for a longer duration, it can result in an increased amount of shadow pages (Refer SAP Note 2100009 for more details).
Since the allocated space doesn’t automatically reduce, it becomes necessary to perform data reclamation.
Read More – Setting up Multi Tier Replication Setup, click here
Replication Modes
In a typical setup, we have two replication modes:
1. Primary to Secondary (SYNC Mode)
2. Secondary to Disaster Recovery (DR) (ASYNC Mode)

Checking Unused Space
To check the unused space, you can refer to the SQL Statement Collection for SAP HANA (1969700).


Also validate and take screenshot of /hana/data and /hana/log volume at File system level.
DB OS Cluster Status
Before initiating the data reclamation process, it’s important to place the HA cluster in maintenance mode at the OS level. This can be verified using the command `crm status`.
SAP HANA Data Reclaim | Steps Before Data Reclamation
Before starting the data reclamation process, follow these steps:
1. Stop the secondary DB (SiteB) and unregister it.
2. Stop the DR DB (SiteC) and unregister it.
3. Disable replication from the primary DB (SiteA).
SAP HANA Data Reclaim | Data Reclamation Process
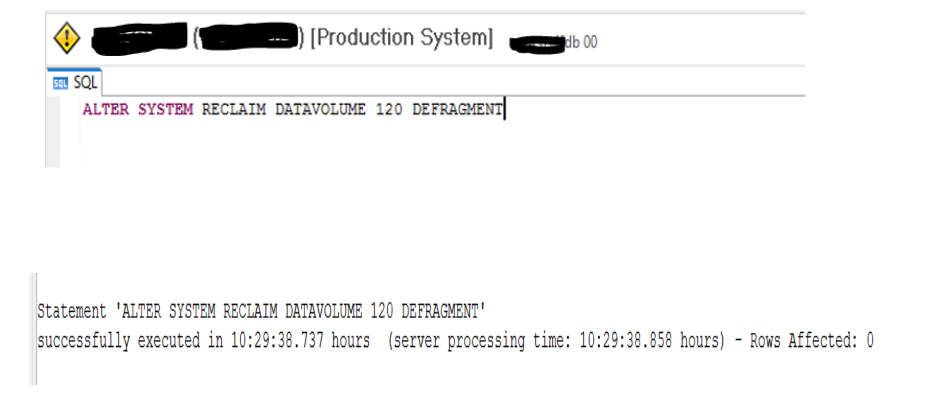
The data reclamation process is executed in the primary DB (SiteA) using the following commands in sql console from OS level or HANA Studion.
ALTER SYSTEM RECLAIM DATAVOLUME 120 DEFRAGMENT;
ALTER SYSTEM RECLAIM DATAVOLUME 110 DEFRAGMENT;
ALTER SYSTEM RECLAIM DATAVOLUME 115 DEFRAGMENT;
If you wish to perform log reclamation, you can use the following SQL query:
ALTER SYSTEM RECLAIM LOG;
Steps After Data Reclamation
Once the data reclamation process is complete, follow these steps:
1. Enable replication in the primary DB (SiteA).
2. Register and start the secondary DB (SiteB) in SYNC mode.
3. Register and start the DR DB (SiteC) in ASYNC mode.
Validate the file system of /hana/data and /hana/log at file system level and monitor the replication status as it will be in Full Replica Mode and ensure that it is completed and all systems are in SYNC status.
Finally, remove the DB cluster from maintenance mode(SiteA—-SiteB> and validate it using the `crm status` command in OS.
How does this process impact performance metrics
The HANA Data Reclaim process can have a significant impact on the performance metrics of your HANA Database. Here’s how:
1. Disk Space Utilization: The primary purpose of data reclamation is to free up disk space. This can lead to a decrease in the disk space utilization metric, which measures the percentage of the total disk space that is currently being used¹.
2. Database Performance: By freeing up disk space, data reclamation can improve the overall performance of the database. For instance, operations that require disk space (such as creating new tables or adding entries to existing tables) can be performed more quickly when more disk space is available¹.
3. Network Performance: The data reclamation process involves moving and rearranging data, which can increase network activity. This could temporarily impact network performance metrics, such as latency and throughput⁴.
4. System Downtime: The data reclamation process requires the database to be taken offline temporarily. This can increase system downtime, which is a metric that measures the total time that the system is unavailable or offline³.
5. Cost Efficiency: By reducing the need for additional storage space, data reclamation can lead to cost savings. This can improve cost efficiency metrics, such as the cost per unit of data stored.
Conclusion
The process of data reclamation is a crucial aspect of database management. It not only helps in optimizing the performance of your HANA DB but also contributes to significant cost savings. By following the steps outlined in this guide, you can successfully perform a data reclamation process in your DB cluster. Remember, a well-maintained database is the backbone of any successful business operation. Happy data reclaiming.
Resources
(1) SAP HANA Troubleshooting and Performance Analysis Guide – SAP Online Help.
(2) Mastering SAP HANA Troubleshooting
(3) Troubleshooting HANA Performance issues | SAP Help Portal